-

关注我们
李林 若朴 编译整理 量子位 出品 | 公众号 QbitAI
少年,你知道Jeff Dean么? 传奇一般的Jeff Dean现在领导着Google Brain团队,也是Google研发群组的高级研究员(Senior Fellow)。近日,Jeff Dean为YC AI小组的同学讲了一堂时长近1小时的课程,讲述了目前Google目前在人工智能方面的研究和进展。 这节不容错过的AI课程,现在有两个观看方式: 第一:视频方式。 科学前往YouTube(地址:https://youtu.be/HcStlHGpjN8),或者查看我们搬运回来的视频。 第二:图文方式。 Jeff Dean这节课配有86页PPT,我们也把全部内容搬运过来,空耳听译了Jeff Dean对每一页的讲述,然后整理配发为每一页的要点。 所以,开始吧~ 视频在此 PPT讲义在此
我会全面地讲一讲我们正在用深度学习处理哪些任务,正在建立怎样的系统来提升深度学习的速度。 这份PPT是很多人合作的成果,包括我领导的Google Brain团队。
Google Brain团队的任务是让机器更智能,进而让人们生活得更好。
为了达到这个目标,我们:
Google Brain的主要研究领域有以上这些。
我今天主要会讲到红色的这些:
也会涉及一些感知领域的研究。
年初,我写了一篇博客,总结2016年我们团队都做了哪些工作。 http://research.googleblog.com/2017/01/the-google-brain-team-looking-back-on.html 博客中的每一条超链接都指向了这项工作的成果展示或论文。
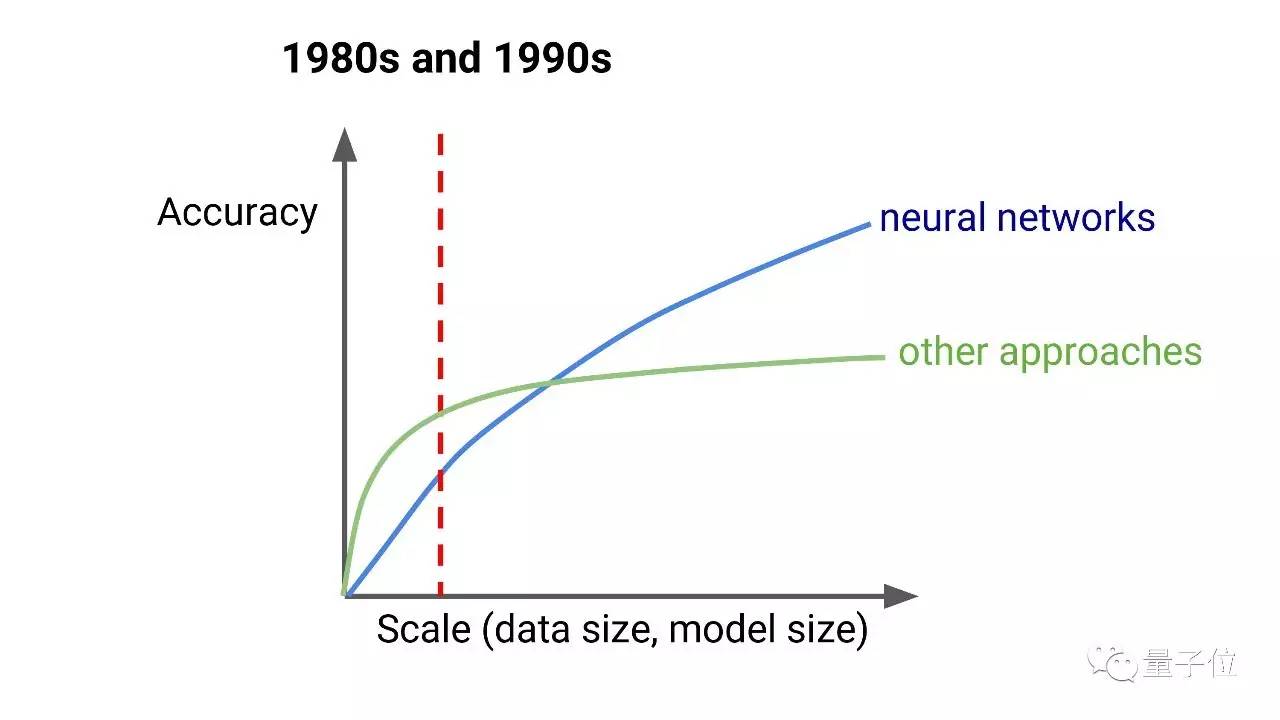
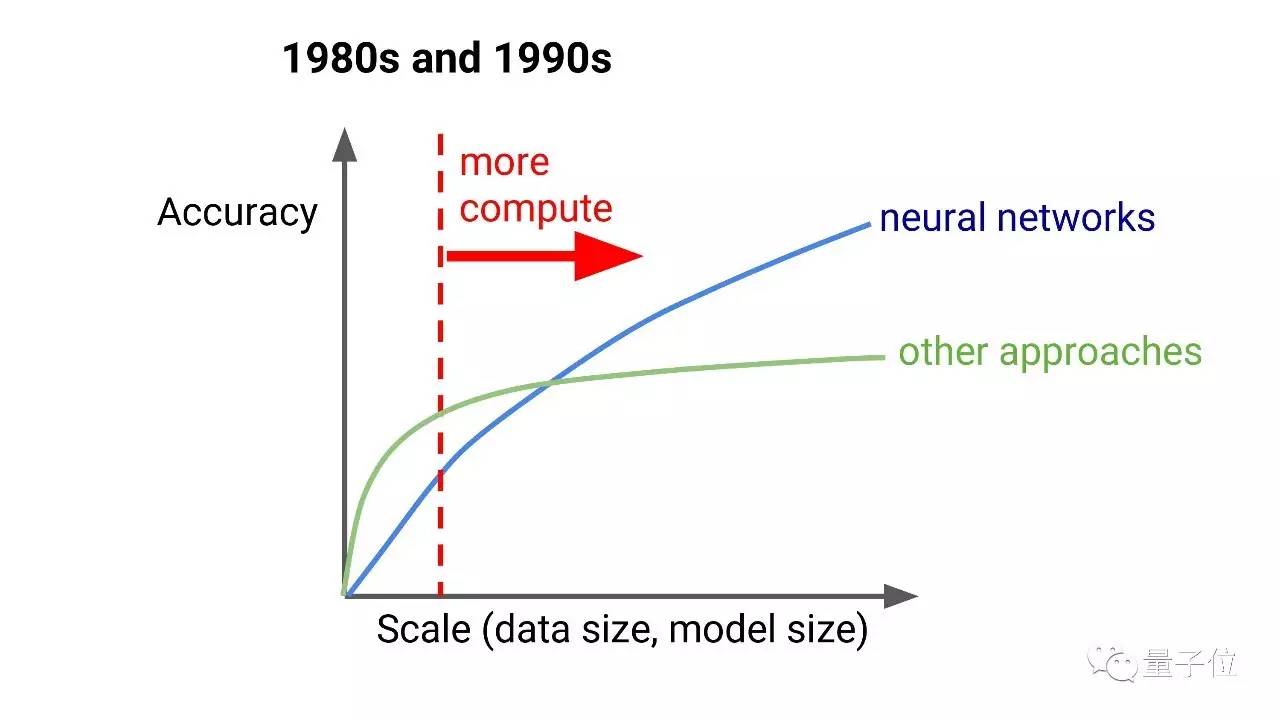
你们可能都在做AI相关的创业公司,不过我还是要说,深度学习改变了我们解决很多问题的方式。 在80、90年代,对于很多问题来说,神经网络还不是最好的解决方案,当时训练数据的量、计算力都还不够。所以,人们或者用其他方法,或者用比较浅层的机器学习方法,需要人工进行大量的特征工程。
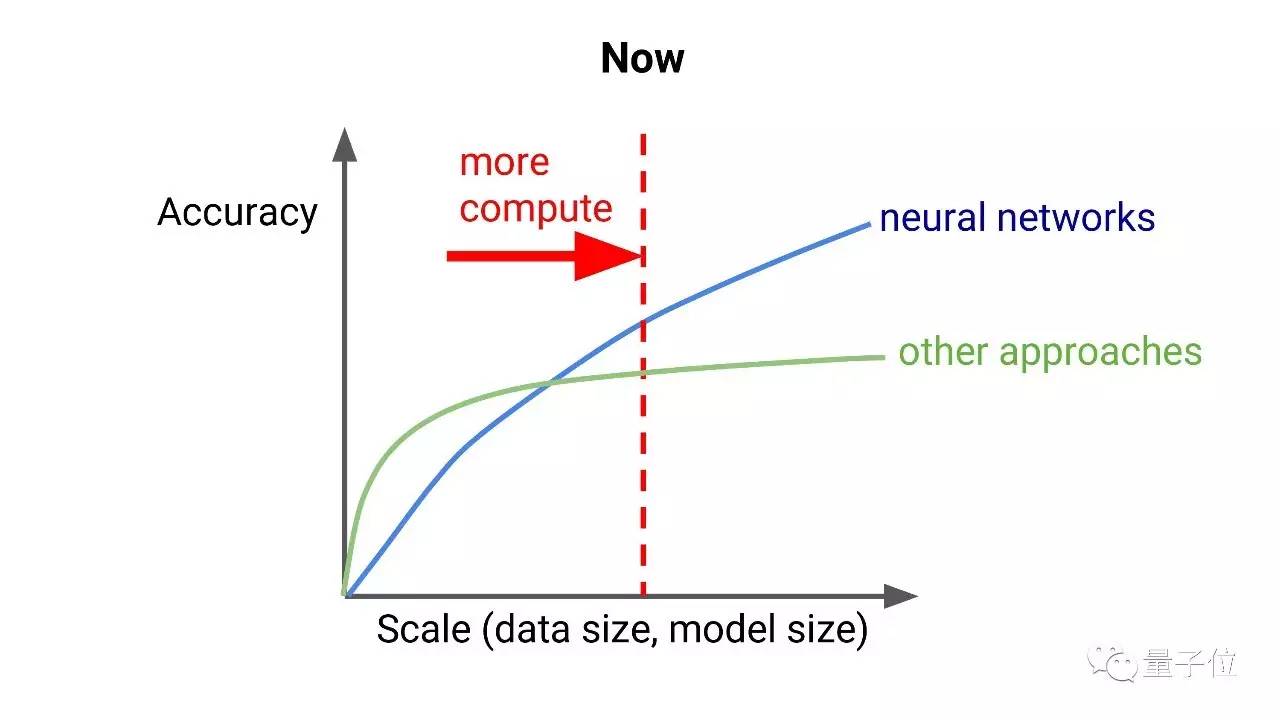
但是现在,我们有了更强大的计算力。 90年代,我的本科论文是关于神经网络的并行训练的,神经网络模型非常吸引我,我想,如果我们能通过并行计算获取更多计算资源,比如说用一台64个处理器的超立方体结构机器,结果我发现,60倍的计算力远远不够,我们需要数十万倍的计算力。
到今天,我们已经有这样的计算能力了。结果就是神经网络成了很多问题的最佳解决途径。
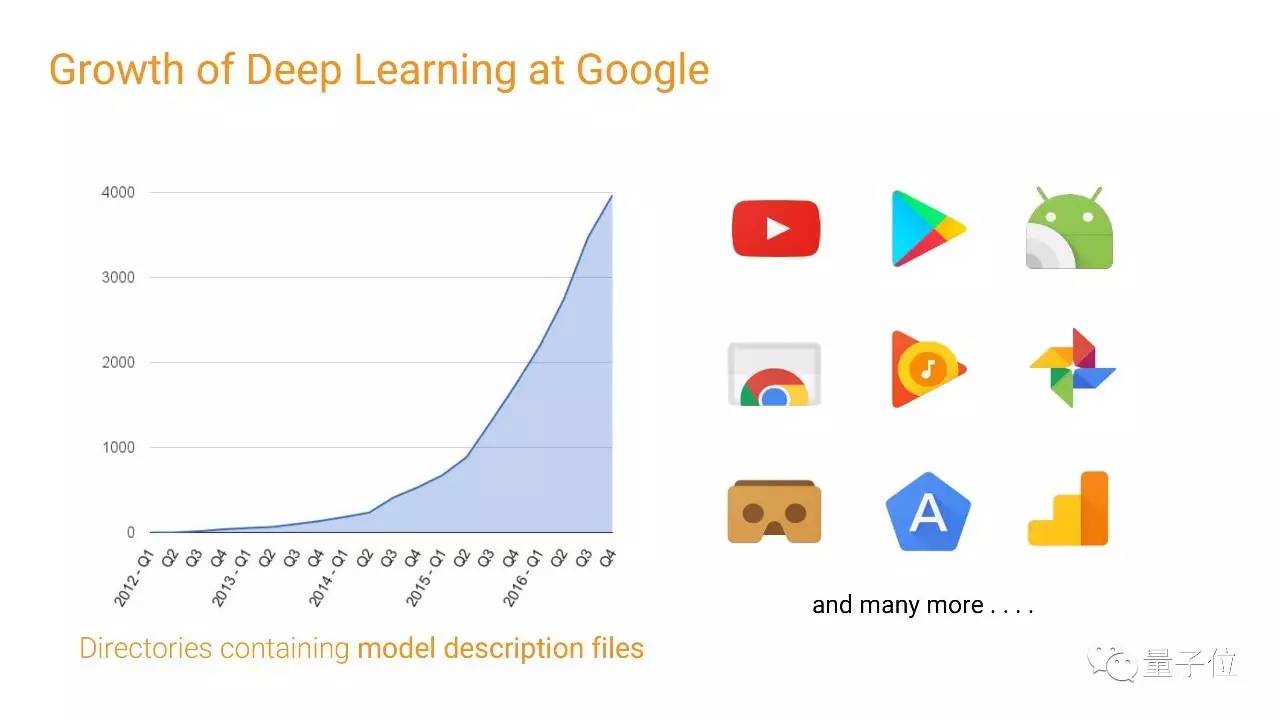
最开始,我们的团队只是想证明大量的计算资源能帮助神经网络解决一些有趣的问题,于是我们做了大规模的无监督学习,那时候甚至还没用上GPU,我们用了16000个CPU核心,做了一些有趣的事情。(量子位注:就是机器从YouTube视频中认出了猫的那一次) 后来,我们把深度学习用到了更多领域,上图左侧是包含我们第一代和第二代(TensorFlow)深度学习框架模型描述文件的程序数量,我们和Google的其他团队合作,把深度学习用到各种产品之中。
我们在工作中关注的一个重点是如何缩短实验的周转时间,提高研究效率。 实验周期需要1个月和实验周期只有几分钟,会带给研究者截然不同的体验。所以,能尽快取得实验结果对我们来说非常重要。
为此,我们要建造正确的工具。
TensorFlow就是我们为解决深度学习问题而建造的第二代系统,它从一开始就是作为一个开源系统而打造的。 量子位注:我们之前发文介绍过Google是怎样管理TensorFlow这么庞大的开源社区的:TensorFlow技术主管详解:Google是怎样管理开源软件的
TensorFlow的目标是,建立一个呈现机器学习创意和系统的通用平台,并让这个平台在研究和生产环境中都成为世界最佳,再通过开源,让它成为所有人的平台,而不只是Google的。
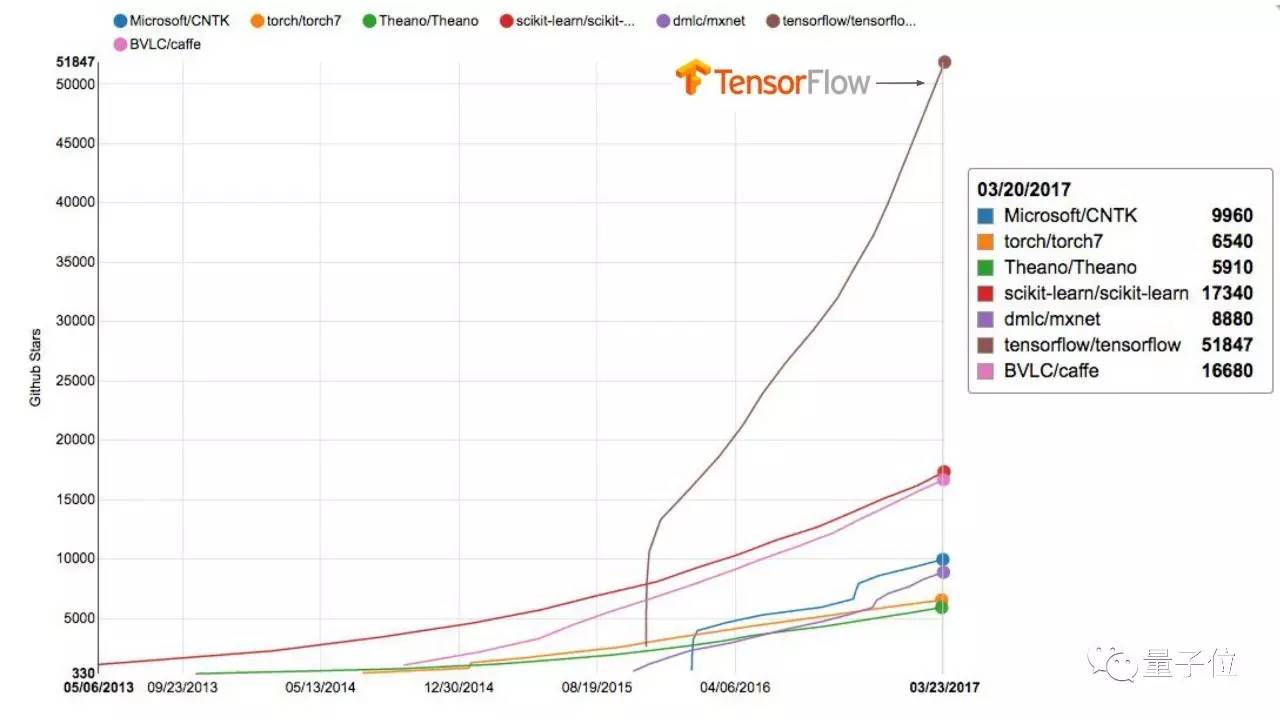
这是GitHub星标数的趋势图,你可以看到TensorFlow与其他机器学习框架的对比。 我想,TensorFlow在研究中足够灵活,又很容易部署到实际产品上,还能在多种环境中运行,这些特性很有吸引力。
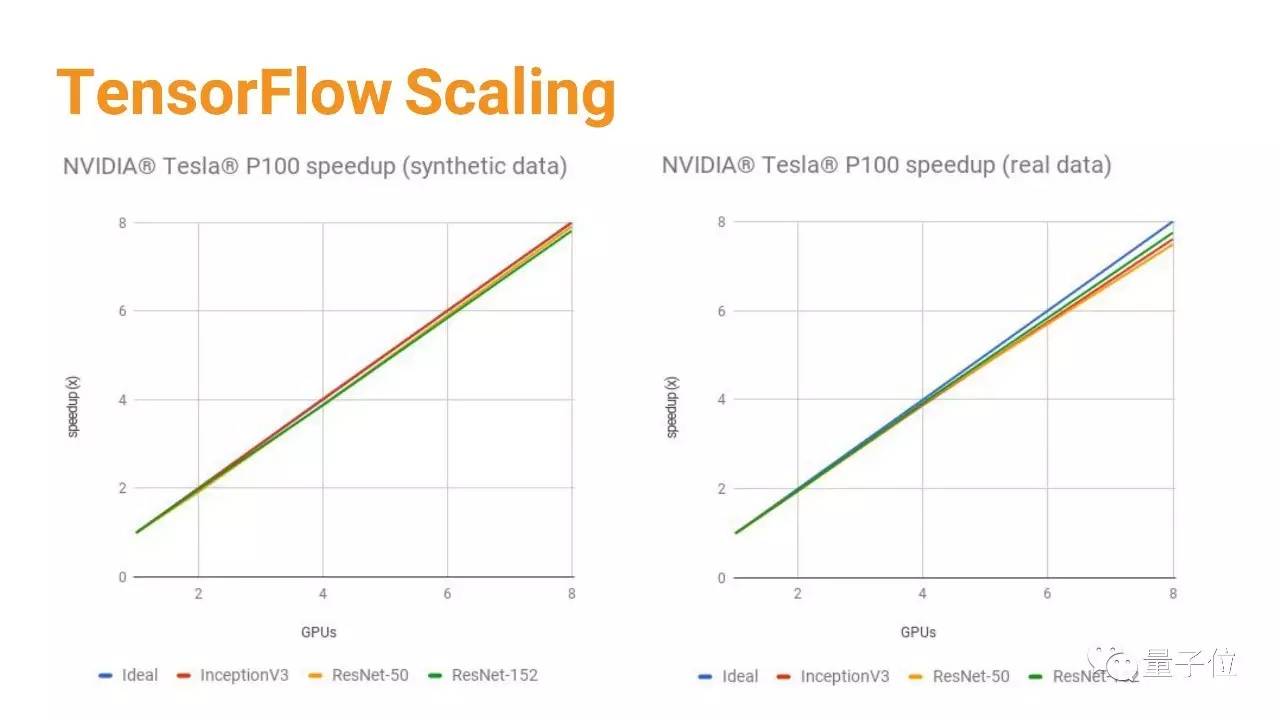
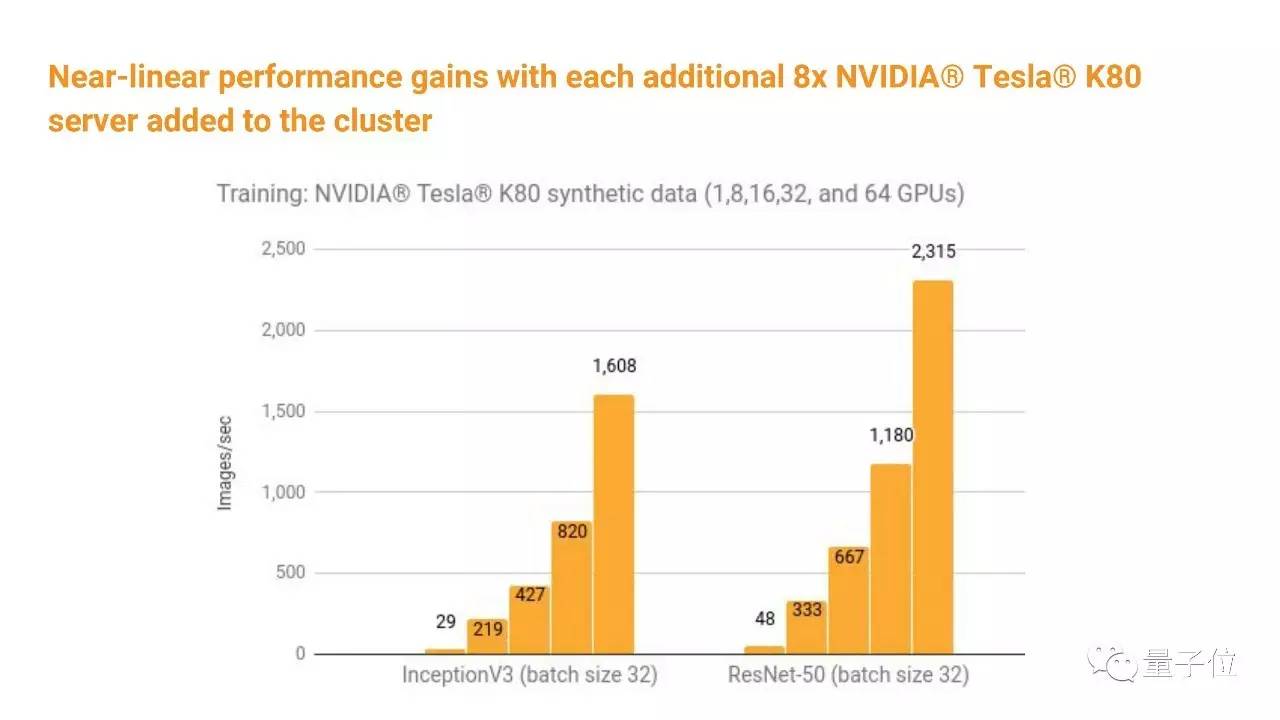
我们经常会做一些基准测试,这些测试显示TensorFlow的可扩展性还是不错的。 其实我们很重视速度。 在TensorFlow刚发布的时候,我们推出了很多教程,但是当时我们犯了一个错误,我们发布的教程代码追求清晰、解释详细,但忽略了性能,于是很多人模仿那些代码来建立高效的TensorFlow模型。后来我们逐渐更新了那些代码,对代码的清晰程度和性能同样重视。
在很多任务上,TensorFlow支持多达64个GPU,还能随着GPU的增加保持性能的线性提升。 如果你听说TensorFlow很慢,不要信��
我们还支持多种平台,包括iOS、Android、CPU、GPU、我们自己的TPU,还有Raspberry Pi等等。
我们还支持各种变成语言,目前支持得最好的是Python,C++做得也不错。
除此之外,我们还有个不错的用户基础。
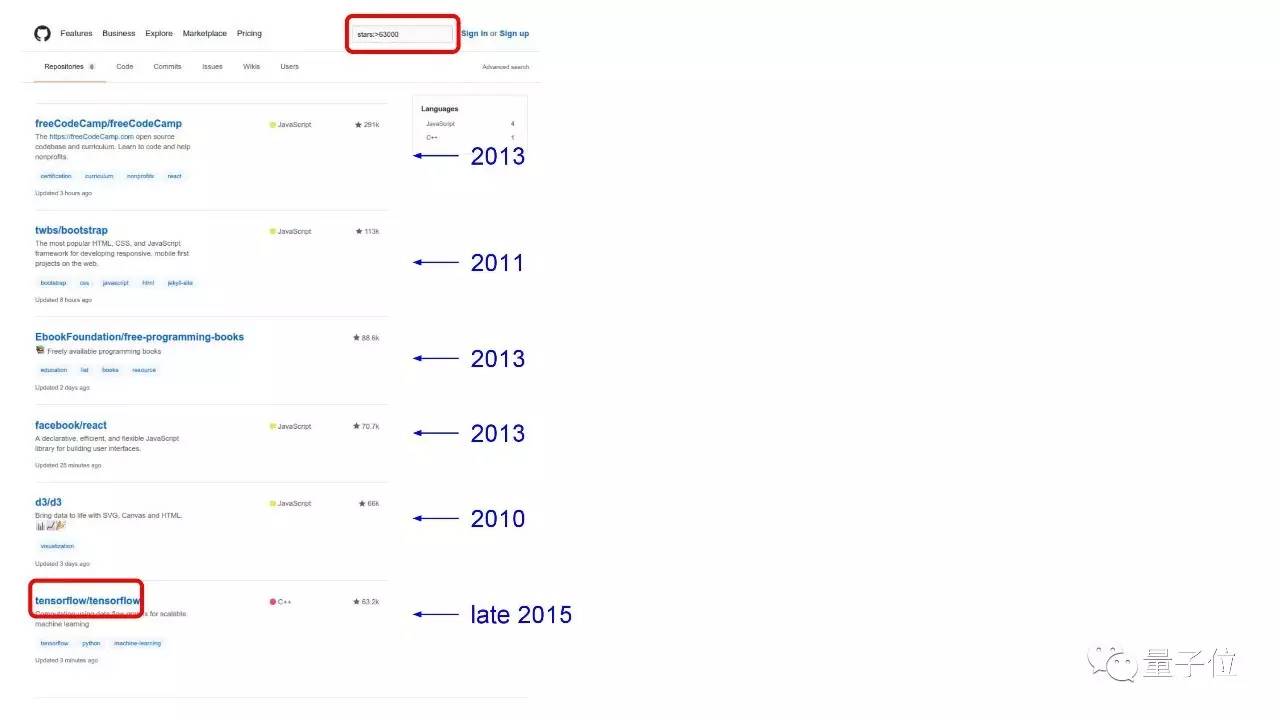
在GitHub上最受欢迎的程序里,我们排第6。前5名要么是JS,要么是LISP编程书。
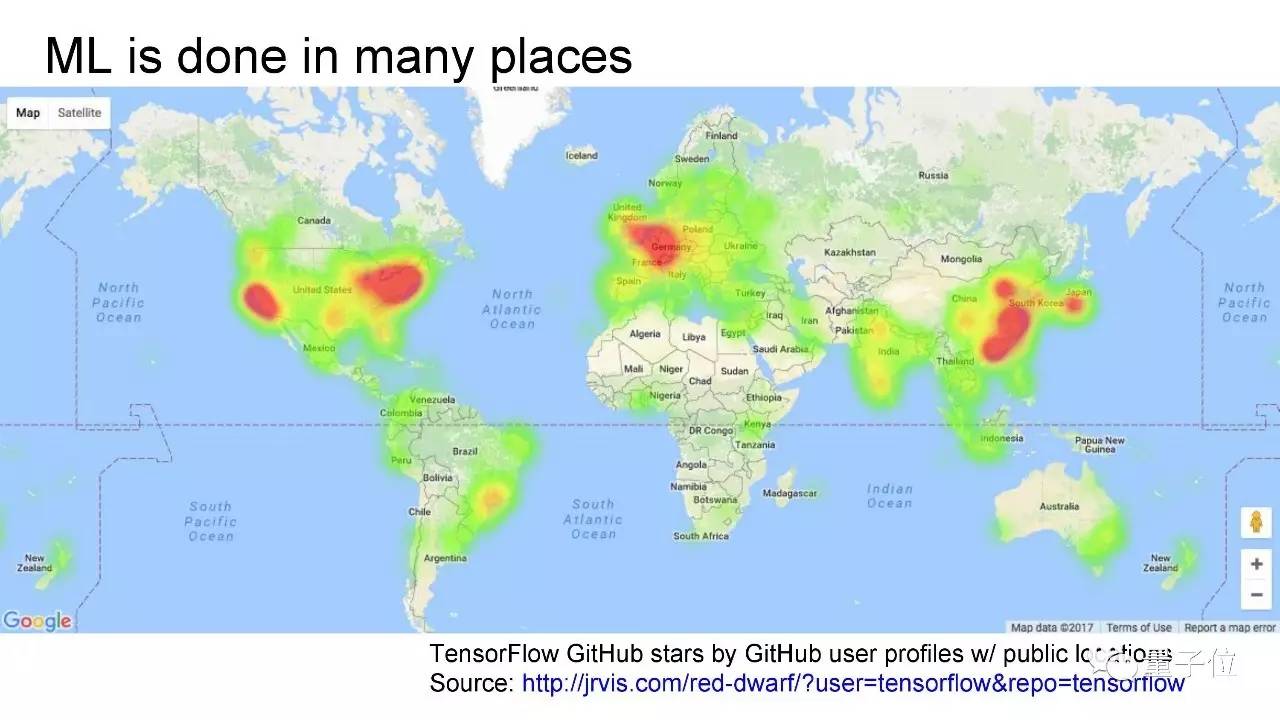
这是世界上为TensorFlow标星的人口分布,全世界几乎都在用机器学习。
TensorFlow在全世界有近千人的外部贡献者,为它增加功能、修复bug、改进系统。 各种机器学习课程中也在越来越多地使用TensorFlow。
接下来我要谈一谈深度学习在Google具体产品中的应用。Google Photos是个很好的例子,计算机视觉让机器能知道人们的照片中有什么,照片中发生了什么事情。
作为人工智能领域的创业者,你们需要关注各种机器学习成果,很多时候,你可以使用其中的方法,把它用到另一个数据集上,就可能有意想不到的发现。 给定一张图片,让机器预测其中的关键像素,是一个常用的模型,有很多种实现方式。 不过,我们的做法是用一个能实现这种功能的模型,迁移到各种其他任务上。
计算机视觉公司Clarifai的创始人Matt Zeiler是我之前的暑期实习生,我们和街景团队合作,识别街景照片中的文字。
训练数据就是人类手工圈出了文字区域的照片,任务是让机器预测普通街景照片中哪里有文字,选定区域之后,就可以通过OCR来识别这些文字了。
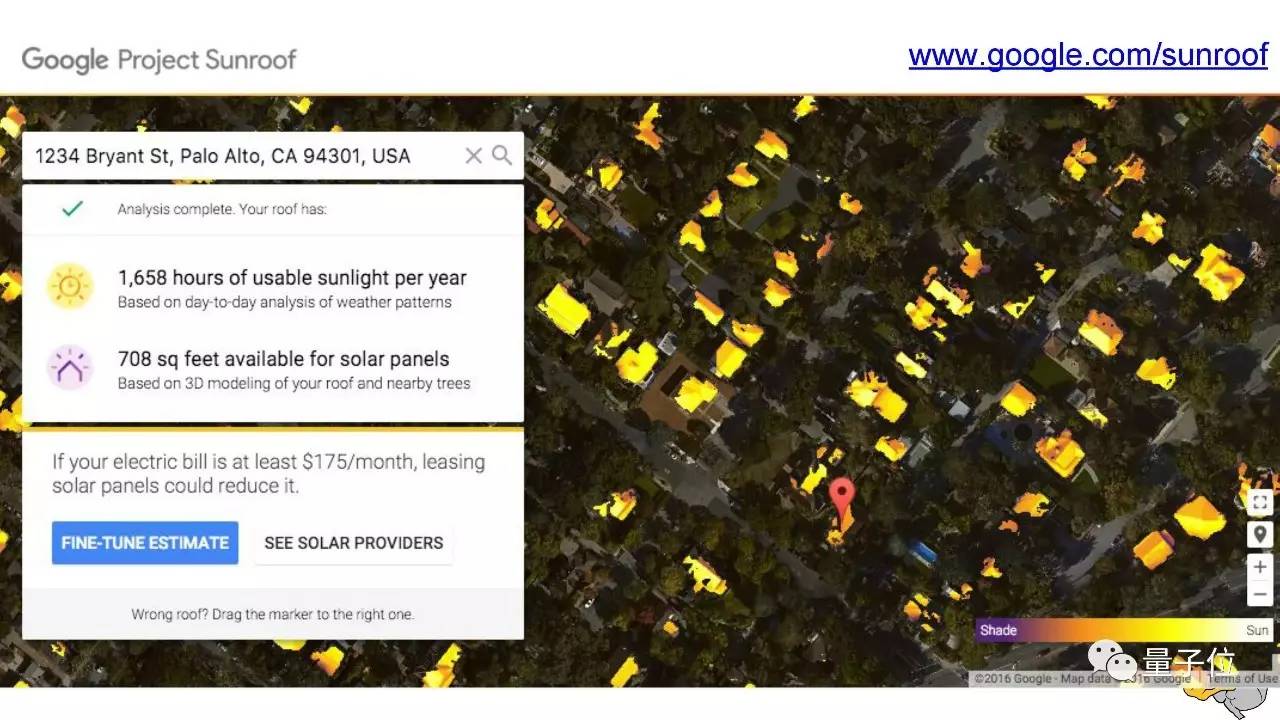
后来地图团队决定开发另一个程序,来识别你家房顶适不适合采集太阳能,装上太阳能板可以生产多少电。 这个程序的第一件事是在图中找出房顶,这和找到文字区域的模型不完全一样,但其实只是换了一种训练数据。
我们还把这个模型用到了医疗领域。
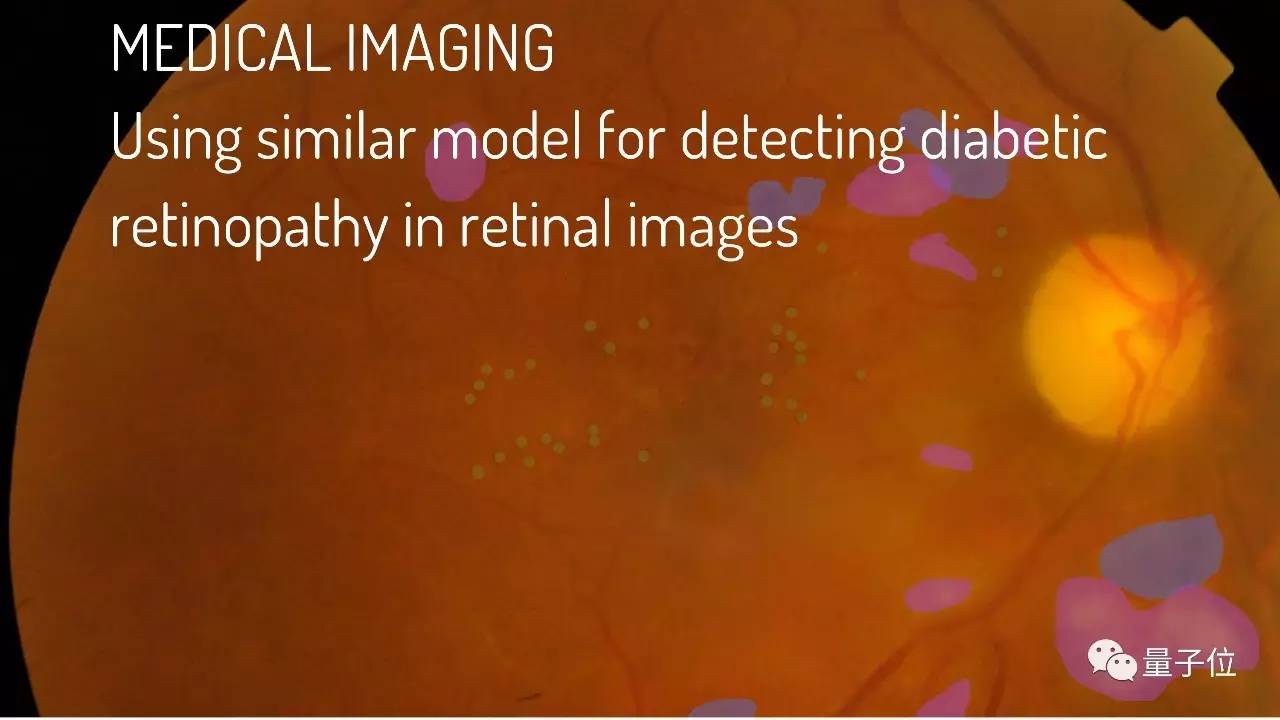
还是一样的基础模型,我们用它来解决医学图像问题。 具体来说,是用在眼科检查上。我们让算法从上图这样的视网膜图片上,分辨出是否有糖尿病视网膜病变。 在这个问题上,我们需要识别图上可能是病变的区域,然后再进行图像分类,确定这个眼部照片是否真的有问题。
我们的研究收集了15万张视网膜照片,每张照片找7名眼科专家来标注,然后训练我们的算法。
最后,我们获得了一个识别糖尿病视网膜病变的算法,和8名协会认证的眼科专家相比,算法的准确率和他们的中位数持平,有时还要高出一点。 相关论文: http://jamanetwork.com/journals/jama/fullarticle/2588763
另外,我们可以看到,深度学习在机器人领域也非常用用。 我们在实体机器人和模拟环境中都做了很多实验,还试着让机器人通过模仿人类的动作来学习。
我们建了个“机械臂农场”,摆了很多机器人,让它们学习抓取物体。 我们每天还会把传感器获取的数据收集起来,用它们训练一个模型来优化机器人的抓取技能,这些机器人每天都会提高。 我们公开了这个数据集,其中包含80万次抓取尝试。 项目主页: https://sites.google.com/site/brainrobotdata/home 论文: https://arxiv.org/abs/1603.02199 数据集: https://sites.google.com/site/brainrobotdata/home/grasping-dataset
这张图是我在做动作,试着让机器人模仿。
我们首先让模拟器里的机器人学习人类动作,然后再迁移到实体机器人。效果还不错。
还有一个激动人心的领域,是深度学习在科学研究中的应用。 科学研究通常都会用到高性能计算机上运行的模拟器,它们会产生大量数据,但问题是,模拟器的运行消耗大量资源,价格昂贵。
举个深度学习应用在这里例子,我们可以用模拟器中的数据作为训练数据,运行一小时模拟器,然后用获取的数据来训练一个神经网络,让它来预测分子的性质。 当然,模拟器给出的结果更精确,但神经网络给出结果的速度要快上几十万倍。 相关研究: https://research.googleblog.com/2017/04/predicting-properties-of-molecules-with.html https://arxiv.org/abs/1702.05532 https://arxiv.org/abs/1704.01212
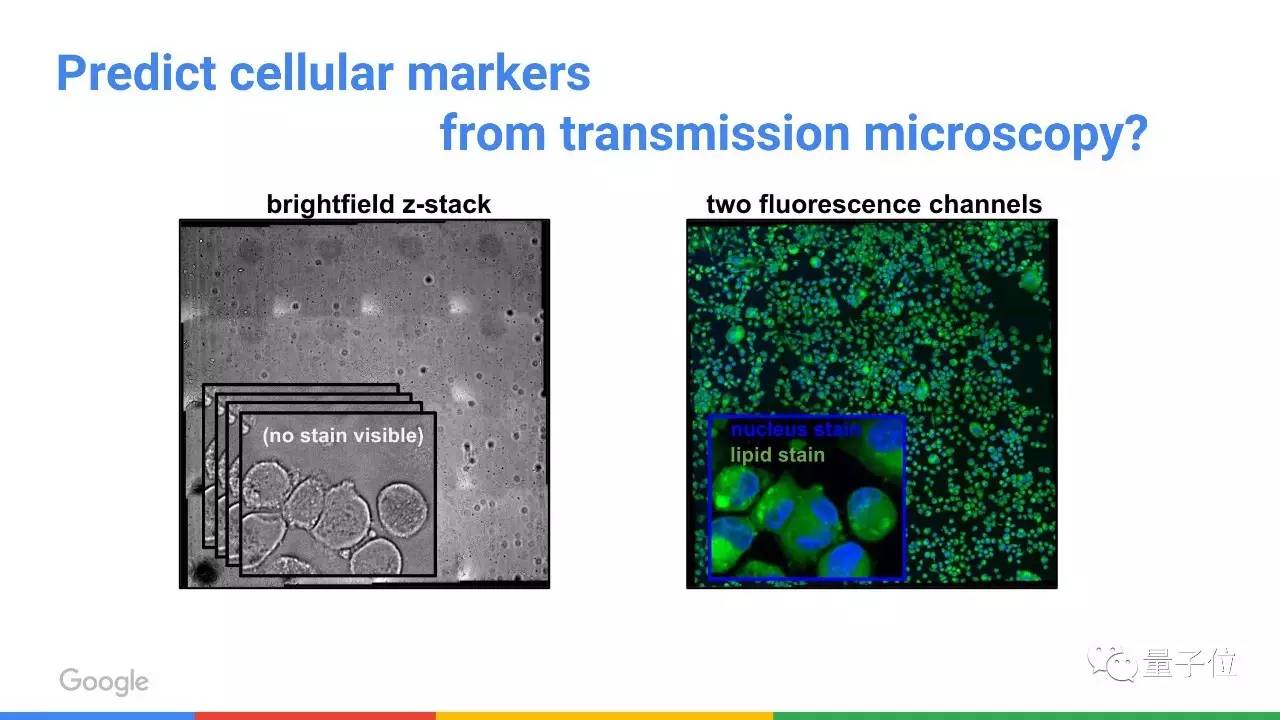
图像处理技术也能用在细胞研究上。怎么用呢?
Google有人做了一个模型,尝试通过一张照片来预测景深。 这是一个pixel to pixel的学习问题,你可以想象,还有很多问题都是类似的。
在拍照中,景深的预测有很多用途,比如说预测一张人像照片的景深。
然后就可以做出一些神奇的效果,比如说保留人像的颜色,把背景变成黑白的,或者让背景变得模糊、给背景加上特定的风格等等。
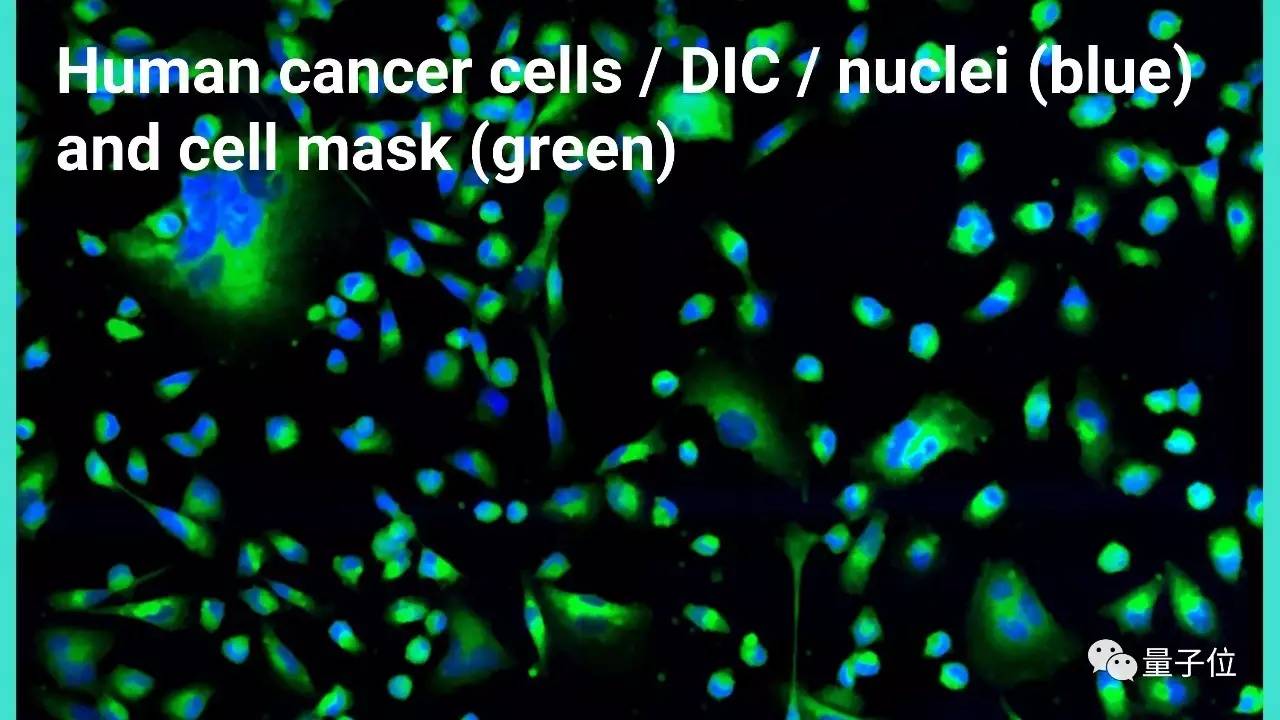
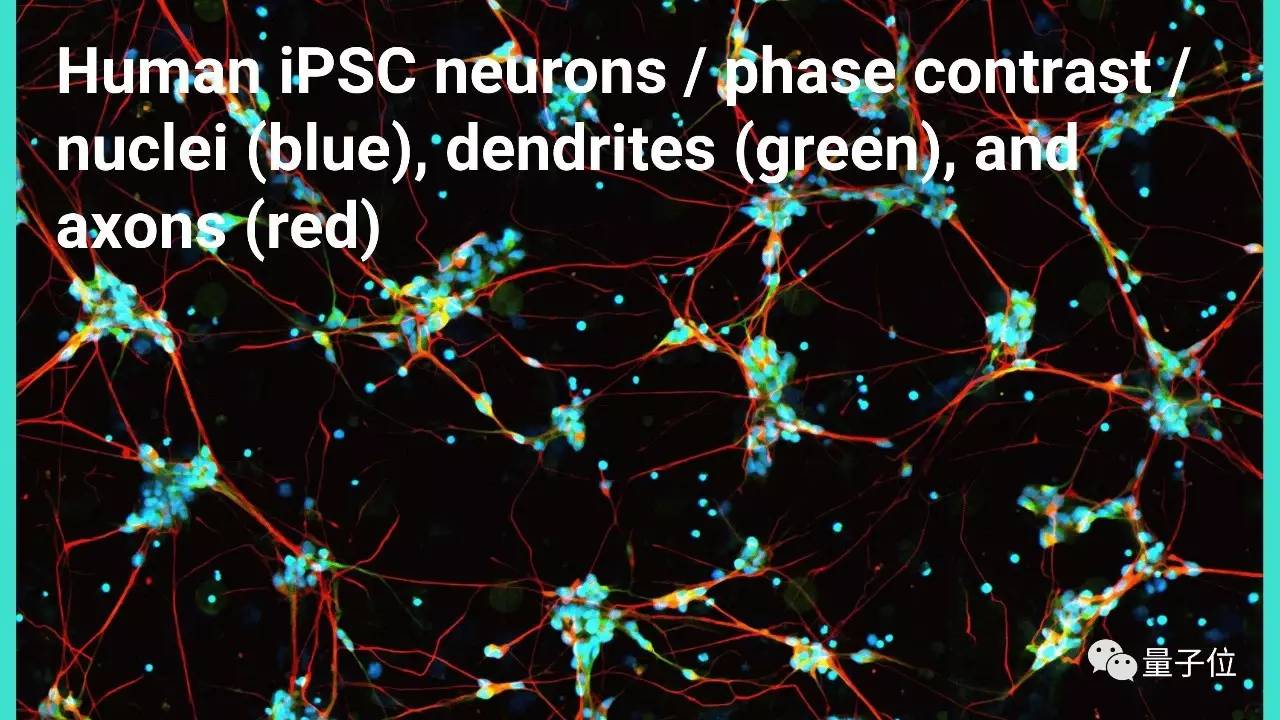
这种模型还有更神奇的用途: 用显微镜原始图像做为输入,可以输出一张染色后的显微镜图像。
这有助于帮人们分清细胞核和它外层的物质。 给细胞染色的时候,通常会伤害细胞的活性,所以这种虚拟染色的功能非常有用,能让你在染色后继续追踪细胞的后续活动。
这种技术也能用来观察神经元的活动。
我们在语言理解领域也做了不少工作。
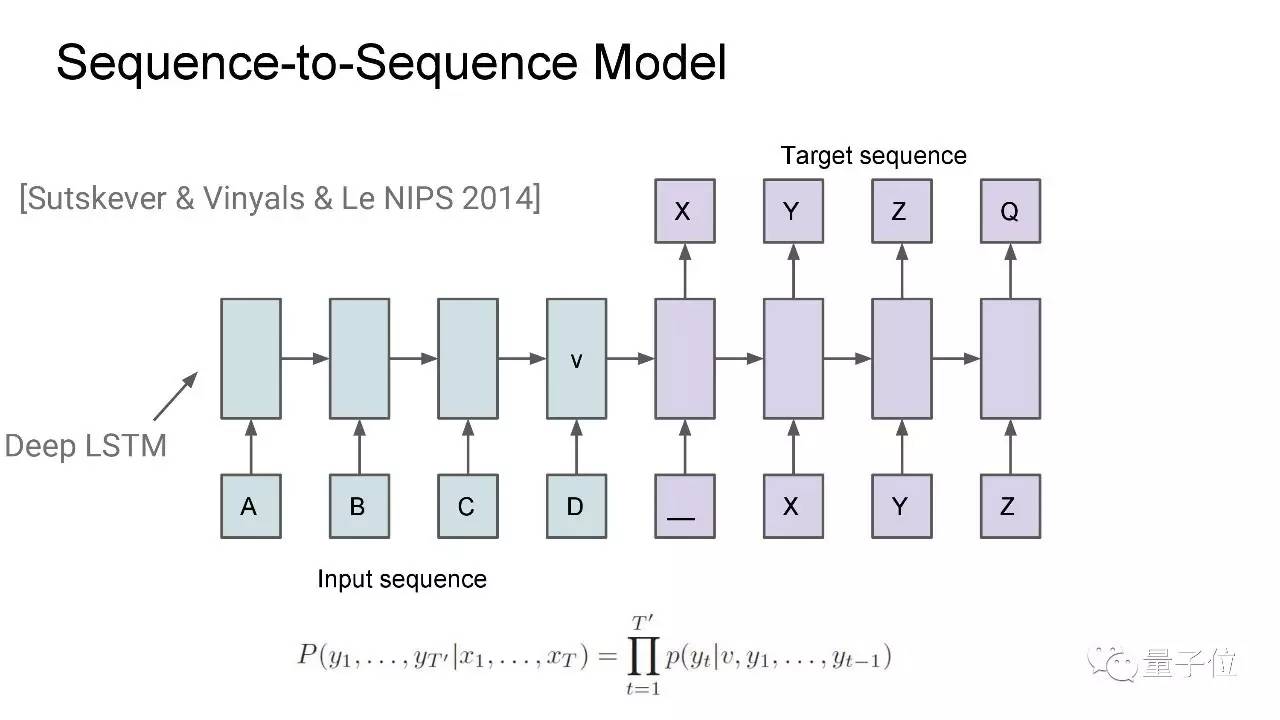
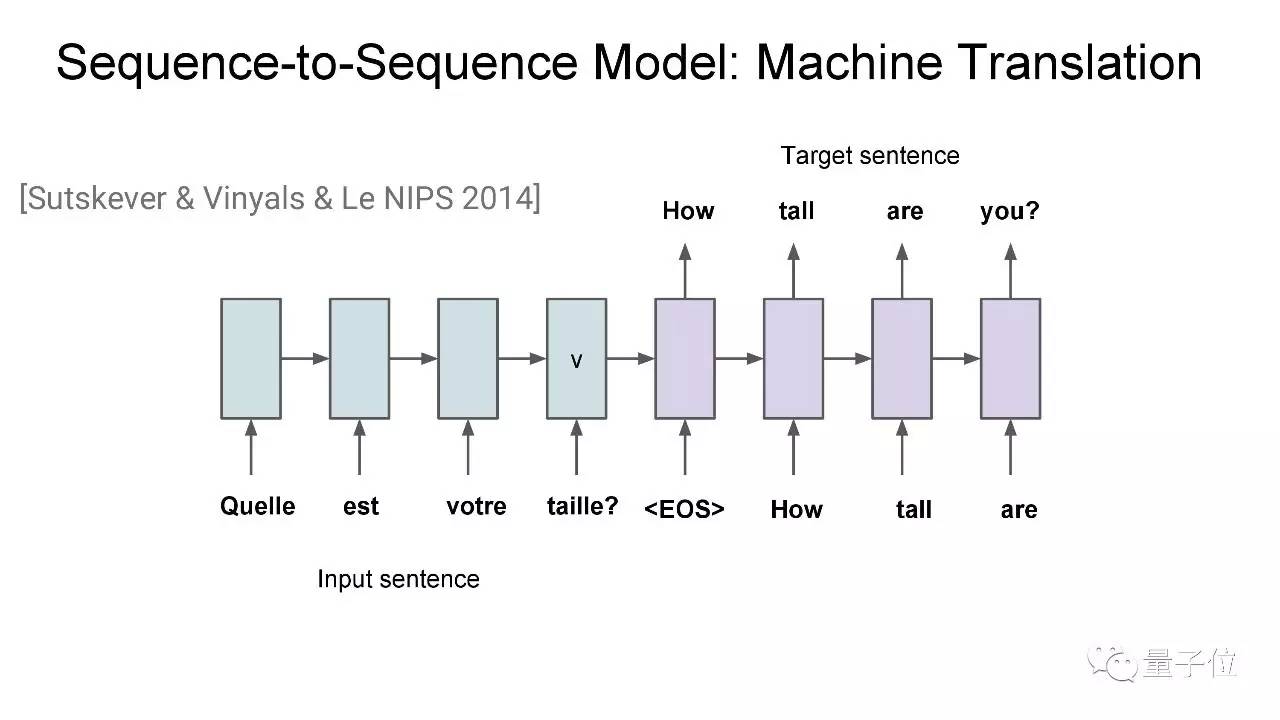
最开始,我们的团队提出了seq2seq模型。给神经网络输入一个序列,它会输出一个预测序列。 seq2seq能用来处理很多问题。
机器学习就是其中之一。 比如说你有一组成对的英语-法语句子,就可以用seq2seq模型,以法语为输入序列,英语为输出序列,将它们对应起来,训练一个RNN。
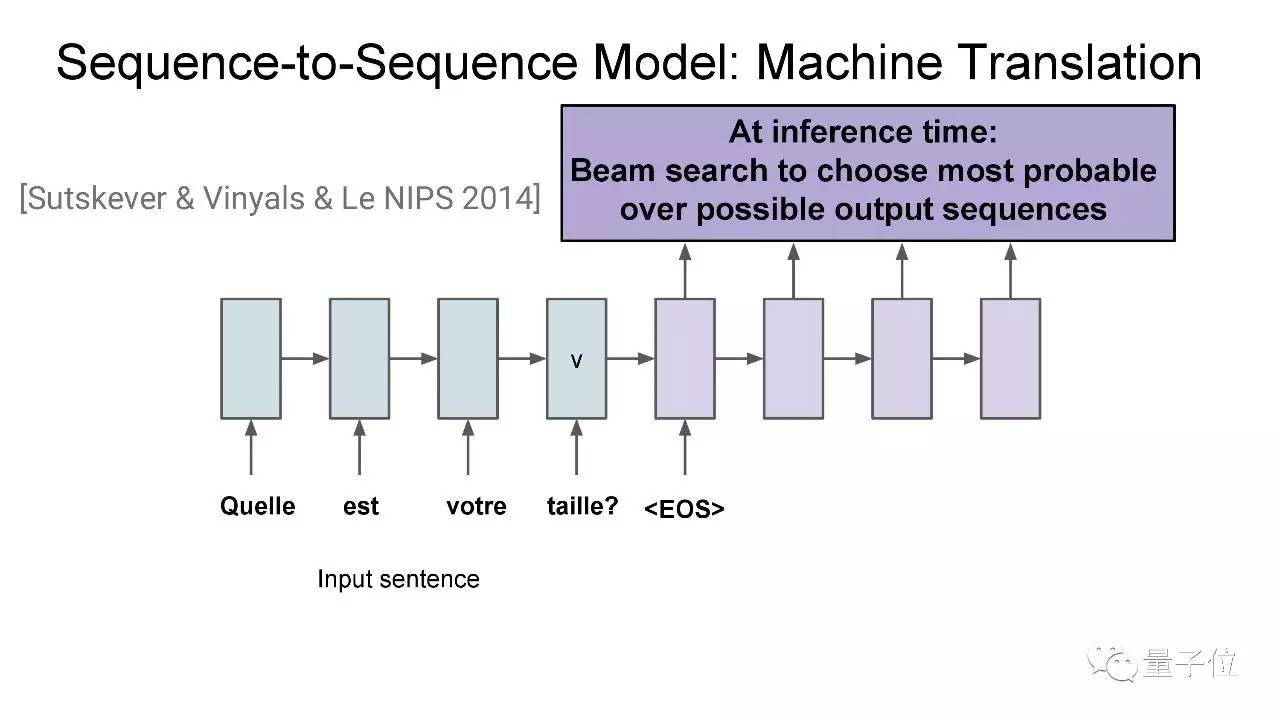
然后你会通过beam search来找到最合适的输出序列。
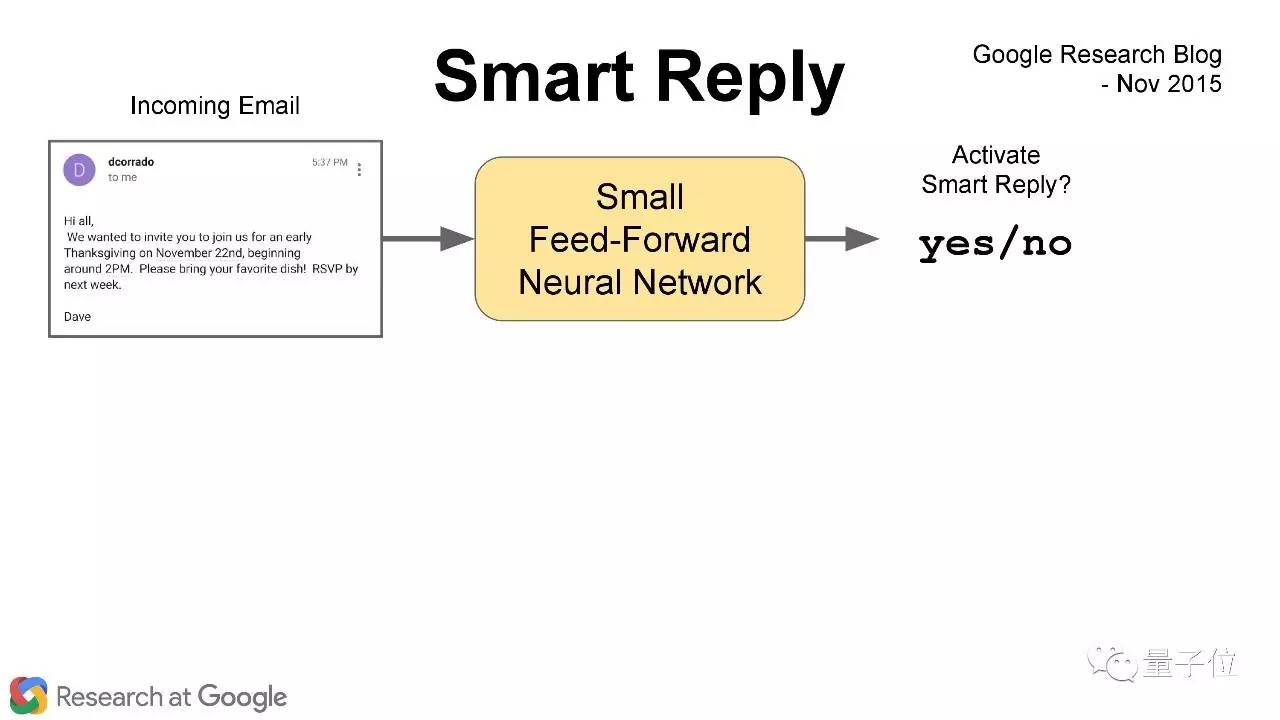
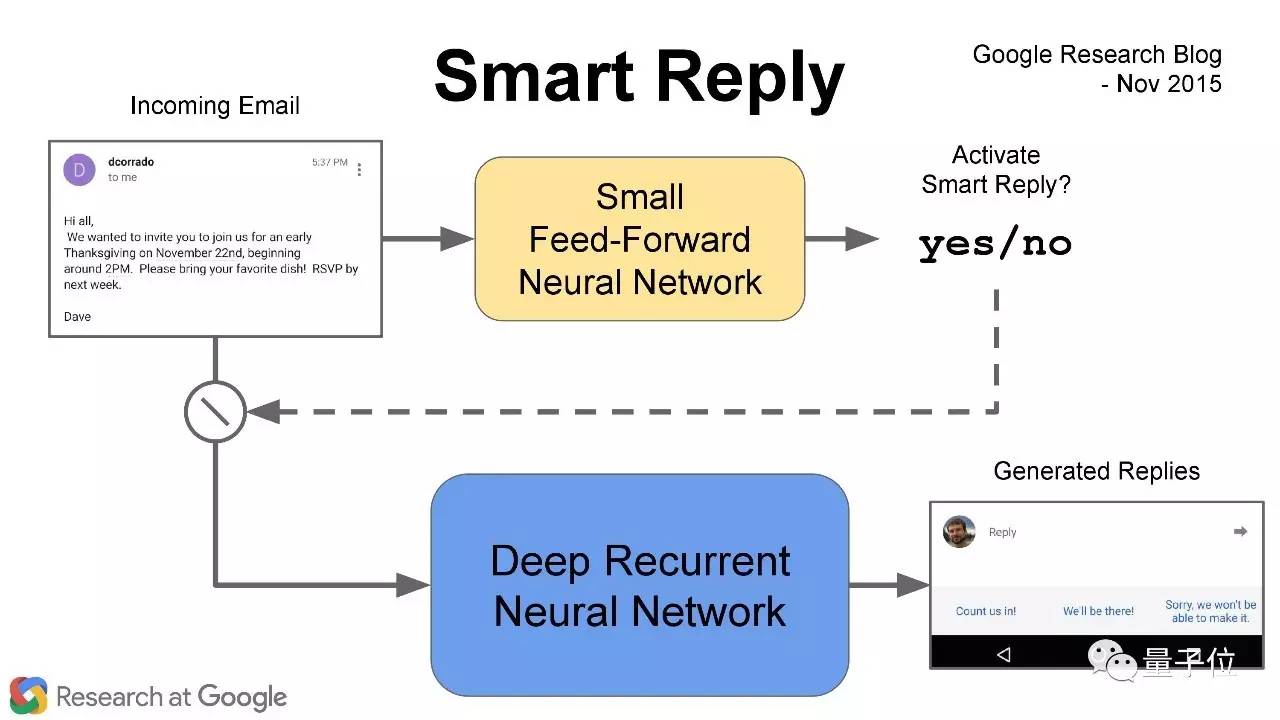
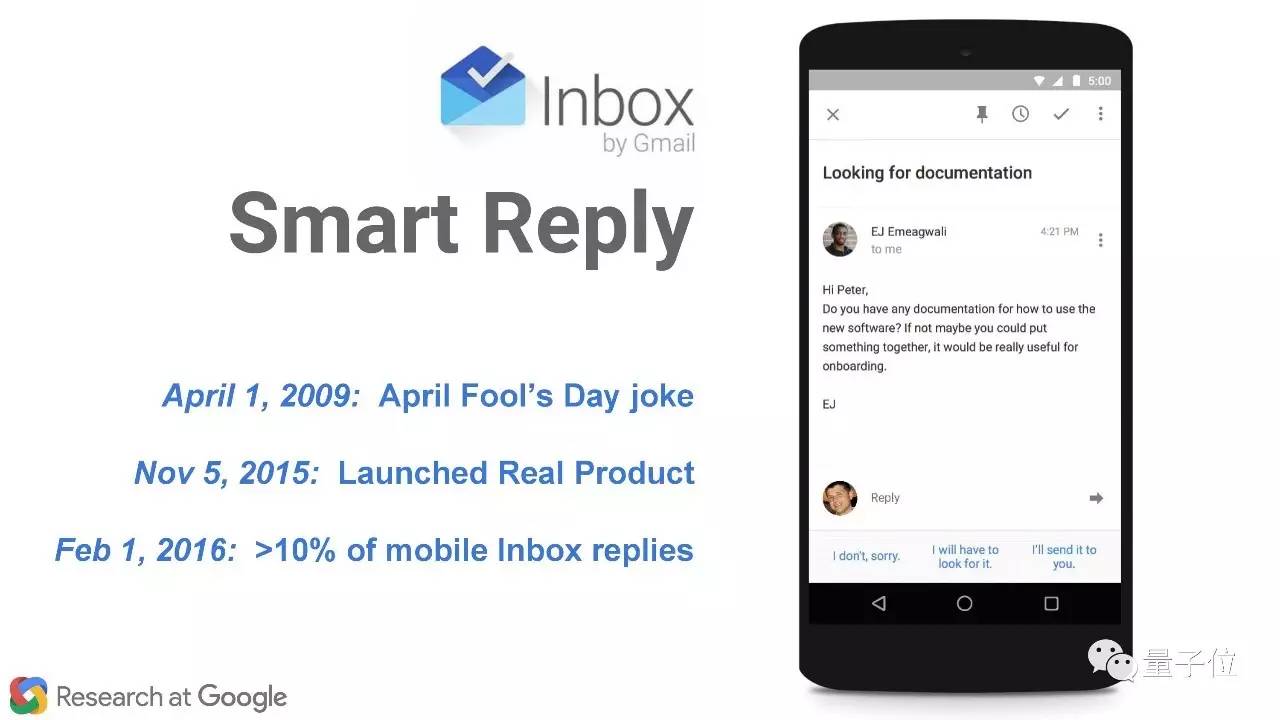
Gmail中的Smart Reply自动回复功能也是seq2seq的应用之一。 举个例子,这是我发给同事们的一封邮件,问大家要不要参加感恩节聚会。这种邮件只需要简短的回复,有了Smart Reply用户只需要选择“是”或者“否”。
我们的seq2seq模型会在用户选了是/否之后,生成一个简短的回复。
这个功能,是2009年Google开的一个愚人节玩笑:“哈哈哈哈我们要帮你自动回复邮件了!” 2015年11月5日,真正的产品发布了;到2016年2月1日,Inbox手机应用中由超过10%邮件是自动回复的。
实际上,seq2seq最具潜力的应用领域还是翻译。 我们把seq2seq用在了在线的谷歌翻译产品中。
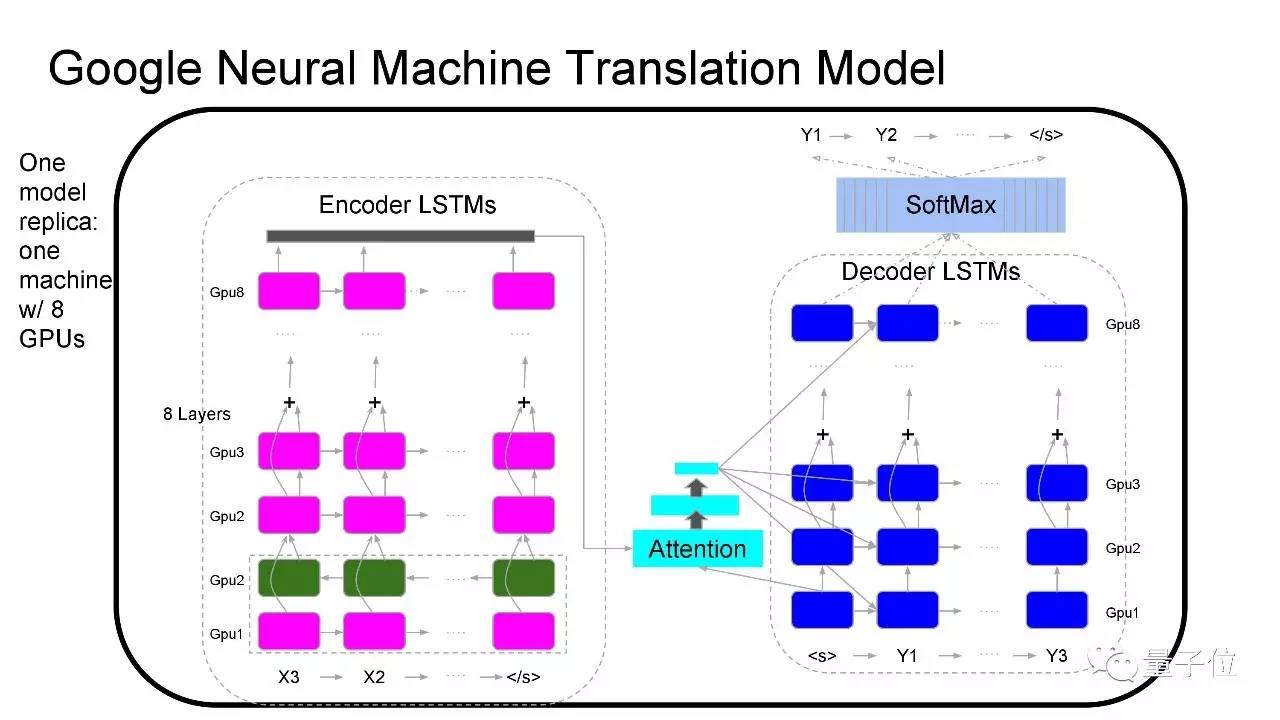
在这篇有很多作者的论文Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation中,我们介绍了机器翻译背后的技术详情。 论文地址: https://arxiv.org/abs/1609.08144
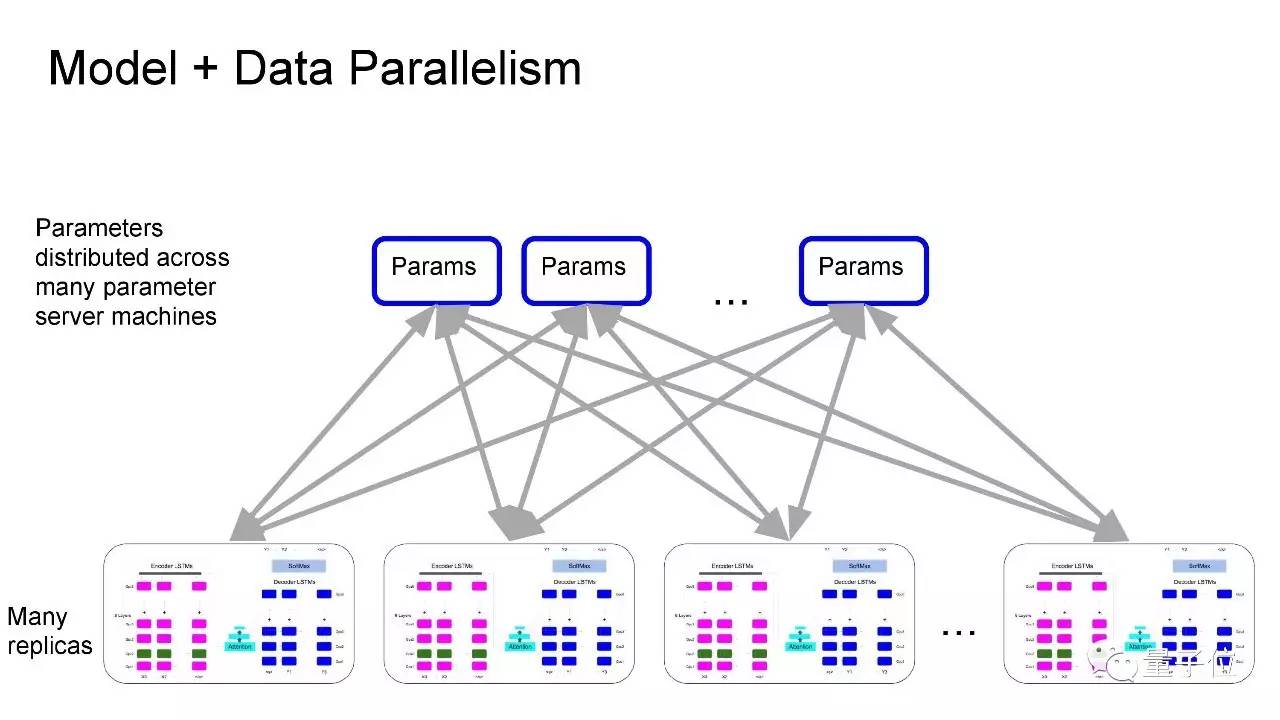
这是我们模型的结构,它包含很深的LSTM stack,每一层运行在不同的GPU上;还有一个注意力模块,追踪所有的状态,决定在生成输出序列的各部分时,分别该注意输入数据中的哪一部分。
此篇文章已有0人参与评论
请发表评论全部评论
|